みなさま初めまして。2019年新卒入社の東川です。
前回はフォルシアで行っているシャッフルランチについて、運営面において工夫した点をご紹介しました。
普段関わりのない社員同士をマッチングシャッフルランチはじめました~企画編~
今回は、シャッフルランチの「グループ分け」について、技術的に取り組んだことをご紹介します。
技術的な課題
シャッフルランチの開催に当たっては、以下のような2つの技術的な課題がありました。
- 参加者の日付の割り振りをどうするか
- 参加者のグループ分けをどうするか
シャッフルランチでは、参加者の負担を減らすため、参加表明からグループ分け、日程調整までを自動で行っています。これを実行するためには、参加者の予定をカレンダーから自動で取得し、予定の空いている日にランチを入れる仕組みが必要です。
シャッフルランチの目的は、普段の業務で関わりの薄い社員同士で一緒にランチに行き、親睦を深めることです。このためには参加者間の「会社での関わり」を点数化し、それが小さくなるようなグループ分けを探し出す必要があります。
前回のシャッフルランチでは6月17日(月)から21日(金)までの5日間に計76名が参加し、次のような2段階の操作で4人ずつのグループに分けました(図1)。
ステップ1では、シャッフルランチと他の予定が重複しないように、76名の参加者を5つの曜日グループに振り分けました。ステップ2では、会社での関わりが小さくなるように、曜日グループを4人ずつのランチグループに分けました。
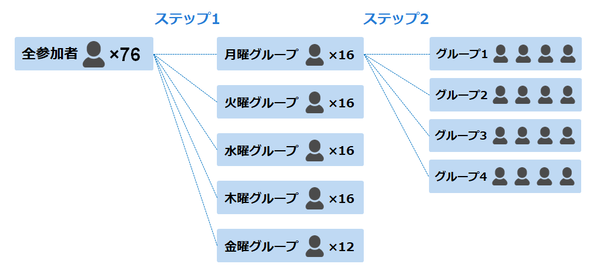 図1:シャッフルランチのグループ分けの方法
図1:シャッフルランチのグループ分けの方法
ステップ1:参加者の日付の割り振り
弊社では社員の予定をGoogleカレンダーで管理しています。GoogleカレンダーのAPIを使用することで、各参加者のカレンダーが取得でき、各曜日のランチタイムが空いているかどうかがわかります。
76名の参加者の各曜日グループへの振り分けは最大2部マッチング問題の一種であり、以下のようにして最大フロー問題(ソースからシンクにどれだけ水を流せるか計算する問題)に帰着され、Dinicのアルゴリズムを使って解くことができます。
まず、ソースから各参加者に容量1の辺、各参加者からランチに行ける曜日に容量1の辺を張ります。続いて、各曜日からシンクへ容量16の辺を張ります(図2)。参加者の割り振りは、ソースからシンクへの流量、即ちランチに参加できる人の人数を最大化するような流れを計算することで得られます。
Dinicのアルゴリズムは、次のような3つのステップからなります。
- 参加者を参加可能な日に順に埋めていく。
- 予定の調整が出来ない人が来た場合、予定の調整が出来る人を別の日に移す。
- 2の処理を全員が枠に入れるか、枠に入れない人がいなくなるまで繰り返す。
終了時点での、各参加者から曜日への辺で正のフローがある辺を探すことで「誰がどの曜日に参加するか」を求めることができます。
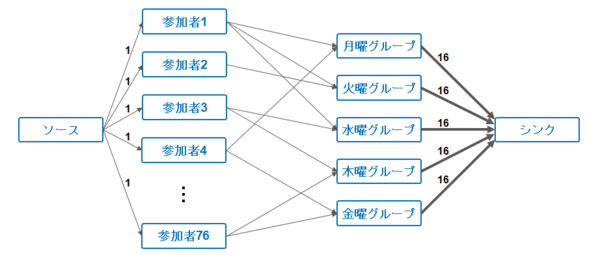 図2:各参加者の曜日グループへの割り振りを、最大フロー問題として扱うためのグラフ構造。
図2:各参加者の曜日グループへの割り振りを、最大フロー問題として扱うためのグラフ構造。(参加者から曜日グループへの矢印は容量1の辺を表します)
ステップ2:曜日グループ内の参加者の組み合わせ
続いて、16名(12名)の曜日グループを、「参加者間の会社での関わりが小さくなるように」4人ずつのグループに分けます。
シャッフルランチの振り分けでは、社員間の「会社での関わり」の指標として、「Slackで共通のチャンネルに加入している数」を用いることにしました。これは、会社での関わりが薄い2人の社員は共通で加入しているSlackチャンネルの数が少ないと考えられるからです。また、Slackのチャンネルの情報を使用することは、指標がリアルタイムで更新されるというメリットもあります。
ステップ2.1:Slackからの情報取得
Slackからの情報取得は3つのステップからなります。
まず、Slackの2つのAPIのメソッド、 channels.listとusers.infoを使用し、チャンネル一覧と全メンバーの情報(IDと名前)を取得します。
続いて、各チャンネルに対してメソッドchannels.infoを使用し、各チャンネルのメンバーのIDを取得します。
そして、取得した情報を組み合わて、誰がどのチャンネルに入っているかを求め、任意の2人の参加者間の共通のチャンネルの数を計算します。
以上の操作で、図3(a)のような社員間の関わりを点数化したような図が出来上がります(説明を簡単にするため、曜日グループのメンバーが6人で、これを3+3のグループに分けるような場合を考えています)。
ステップ2.2:グループ分けの最適化
最後に、最適なグループ分けの計算をします。あるグループ分けのコストを、グループ内の共通のチャンネル数の合計の全グループに対する総和として定義します。このコストが最小になるようなグループ分けが関わりの薄い社員同士のグループ分けになっていると期待されます。
例えば、図3(b)のグループ分け(A-E-FとB-C-D)の点数は(14 + 5 + 7) + (20 + 19 + 5) = 70でコストが高く、会社での関わりの深いメンバー同士でグループ分けがされています。
一方、図3(c)のグループ分け(A-B-DとC-E-F)の点数は(5 + 5 + 3) + (1 + 5 + 8) = 27でコストが低く、会社での関わりの薄いメンバー同士でグループ分けができていることがわかります。
コストの最小化には、ランダムサンプリングと山登り法を組み合わせた方法を使用しました。これはランダムに生成されたグループ分けから始めて山登り法により局所最適解を求め、局所最適解のうち最もコストの低いグループ分けを選び出すものです。
これにより、シャッフルランチの醍醐味である組分けのランダム性を楽しみながらもコストの低いグループ分けを求めることが可能になります。
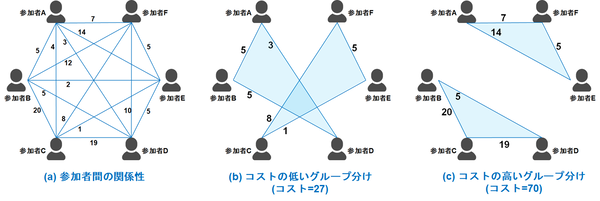 図3:曜日グループ内の参加者のグループ分け
図3:曜日グループ内の参加者のグループ分け(数字は2者間の共通のチャンネルの数を表します)
開発について
開発は私を含む新卒1年目の社員2人と4年目の社員1人の合計3人で行われました。
全体の開発を、
- Googleカレンダーからの予定の取得と参加者の曜日グループへの振り分け
- Slackからの情報の取得
- グループ分けのコストの最小化
という3つのパートに分割し、1人1つ担当する形で進めました。
開発期間が2週間しかなく、通常業務と並行しての作業は難しいところもありましたが、並行作業により時間を短縮できたこととデータの受け渡し方法について3人の連携が取れていたことにより、無事シャッフルランチの開催日に開発を間に合わせることができました。
得られたグループ分けは参加者からも好評であり、「よくシャッフルされていた」「普段業務で関わることのない人と話すことができた」という感想をもらいました。
今後の課題
ただし、組分けのロジックについてはまだまだ改善が必要です。上記の方法ではコストの最小化を曜日グループの中でしか行っていませんが、曜日グループをまたいだ人の入れ替えを考えたほうがより全体のコストを最小化することができると期待されます。
また、今回のシャッフルランチでは会社での関わりの指標として共通のSlackチャンネルの「数」を使用しましたが、これは社員間の関係を点数化するうえで最適な指標とは言えません。
Slackのチャンネルには、会話量やメンバー数の大小で多種多様なものがあるもかかわらず、すべてのチャンネルの寄与を同等に扱ってしまっているからです。
各チャンネルに会話量やメンバー数に応じた重みづけをつけることで、より精密に社員間の関係を点数化する事ができると期待されます。
今後これらの課題を改善して、より良い制度にしていきたいです。
東川 翔
2019年新卒入社。
旅行プラットフォーム事業部にエンジニアとして配属。
早起きにも慣れてきました。


