EC サイトを取り巻く自然言語処理事情
検索プラットフォーム部エンジニアの吉成です。 普段の業務では理化学機器などを取り扱うECサイトを担当しています。
フォルシアは以前より、旅行系サイトやECサイトなどにおける、膨大かつ複雑なデータの高速検索を得意分野としてきました。 さらに近年では、検索に関連する周辺技術にも注目して開発に取り組んでいます。 人間が話したり書いたりする「ことば」をコンピュータに処理させる「自然言語処理」もそのうちの1つです。
フォルシアアドベントカレンダー2020 7日目である今日は、ECサイトを担当するエンジニアである私が、ECサイトにおける自然言語処理で取り組まれているタスク、特にカテゴリ予測と口コミ分析について語ります。
自然言語処理に馴染みのない方にもわかるような説明を心がけますので、現在・未来に自然言語処理がECサイトへともたらすものを考えながら、自然言語処理に興味を持っていただければと思います。ECサイトにおける自然言語処理に興味を持っていただけた際には、この記事が「どのようなキーワードで調べれば良いか」の指針になれば幸いです。
自然言語処理に馴染みのある方には、これまでに身につけてきた技術がECサイトというフィールドでどんなふうに役立てられるのかを考える参考にしていただきたいと思います。
ECサイトと自然言語処理
ECサイトには、たくさんの「ことば」が使われています。商品名や商品の説明文、商品を分類するためのカテゴリやタグに加えて、ユーザが入力する検索キーワードや実際に商品を購入した人が書く口コミなど、「何のために書かれたのか」も「誰によって書かれたのか」も様々です。 そのため、ECサイトは様々な自然言語処理的な課題を抱えています。
今回はその中から、カテゴリ予測と口コミ分析を取り上げたいと思います。
カテゴリ予測
ECサイトにおけるカテゴリ予測とは、その名の通り与えられた商品やサービスのカテゴリを予測する問題のことです。 カテゴリの代わりにタグなどを予測することもあります。 ECサイトで取り扱われる商品数が増加する中で、今までは人手だったカテゴリやタグの付与を自動化する需要も増してきています。
予測する方法には様々なものが考えられますが、既にカテゴリがわかっている商品のデータを大量に用意し、商品名や画像・説明文といった商品情報から予測するモデルを学習することが多いです。 特に、分類に使うのが商品の名前や説明文といった自然言語によるデータの場合、カテゴリ予測は文書分類タスクの一種と言えます。
一般的な分類問題との違いは、多くの場合、カテゴリが図1のような階層構造をなしていることです。
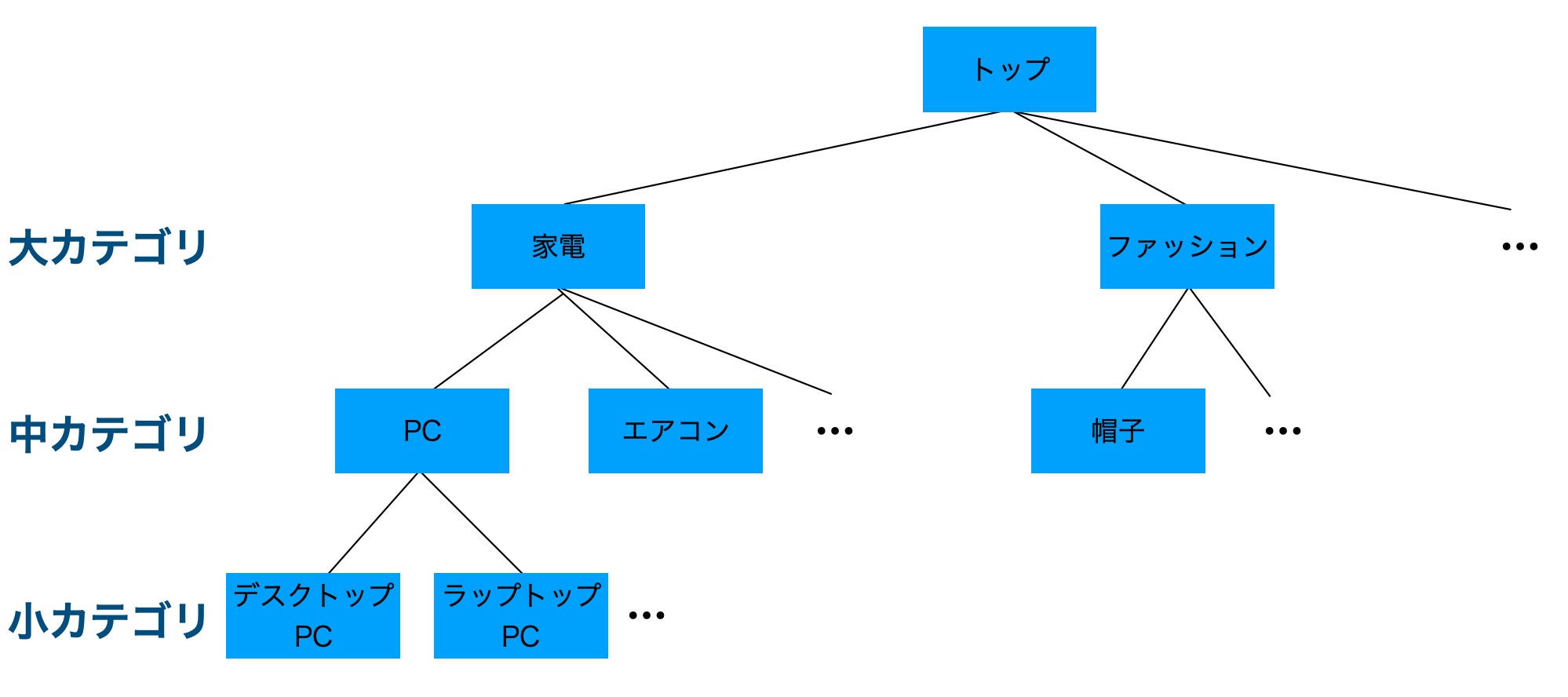
図1: カテゴリの階層構造
商品の階層的なカテゴリ予測に取り組んだGaoら [1] は、現在の階層的な分類の主な課題を2つ挙げています。
- 階層情報をどう表現するのか
- 学習過程における階層の不整合をどう処理するのか
1は、例えば図1中の「中カテゴリ: PC」は「大カテゴリ: 家電」の子カテゴリである、「中カテゴリ: PC」と「中カテゴリ: エアコン」は同じ「大カテゴリ: 家電」を親カテゴリとして持つ兄弟カテゴリである、などのようなカテゴリとカテゴリの間の関係を、カテゴリ予測の機械学習モデルにどうやって組み込むのか、ということです。
Naive BayesやSVM など、基本的な分類モデルの多くは分類対象のクラス (ここでは商品カテゴリ) が階層構造をなすことは前提としていません。
Gaoらは下位カテゴリをベクトルで表現する際に、図2のように上位のカテゴリのベクトル表現を一部として持たせるようにすることで、深層学習モデルにカテゴリ間の関係を組み込みました。
2は、カテゴリ予測の結果が矛盾した場合どう処理するのかということです。図1のカテゴリ階層の例でいうと、大カテゴリを「家電」と予測したにもかかわらず中カテゴリを「帽子」と予測してしまった場合にあたります。
既存のモデルのほとんどは、カテゴリの階層別にカテゴリを予測したり、親カテゴリごとの予測モデルを学習したりしていますが、前者の場合はカテゴリ予測の矛盾に対処できず、後者の場合には子カテゴリを持つカテゴリごとのモデルが必要なので中間層のカテゴリが増えると膨大な数のモデルが必要になります。
Gaoらは深層学習で正解データと現在のモデルの予測との「ずれ」を測るために用いる損失関数を、2つの連続する層の予測が矛盾している場合ペナルティが与えられるように定義して矛盾した予測結果が出づらくなるようにしました。
実は、フォルシアでも商品の自動カテゴリ予測について取り組んでいます。フォルシアでは、ECサイト上で数百万点の商品を取り扱う顧客に対し商品データからの自動カテゴリ予測を提案しました。このときに構築したカテゴリ予測モデルは現在も商用利用されています。
今回はカテゴリ予測の自然言語処理的な側面のみを取り上げていますが、商品画像からのカテゴリ予測も当然考えられます。 現在の EC サイトの多くは商品画像と商品のタイトル・説明の両方がありますし、自動でカテゴリを予測するモデルが一般的に使われるようになるには、まずテキストと画像のどちらか一方だけに拘らず、両方を使ってより精度の高い予測モデルを作ることが先決だと思います。
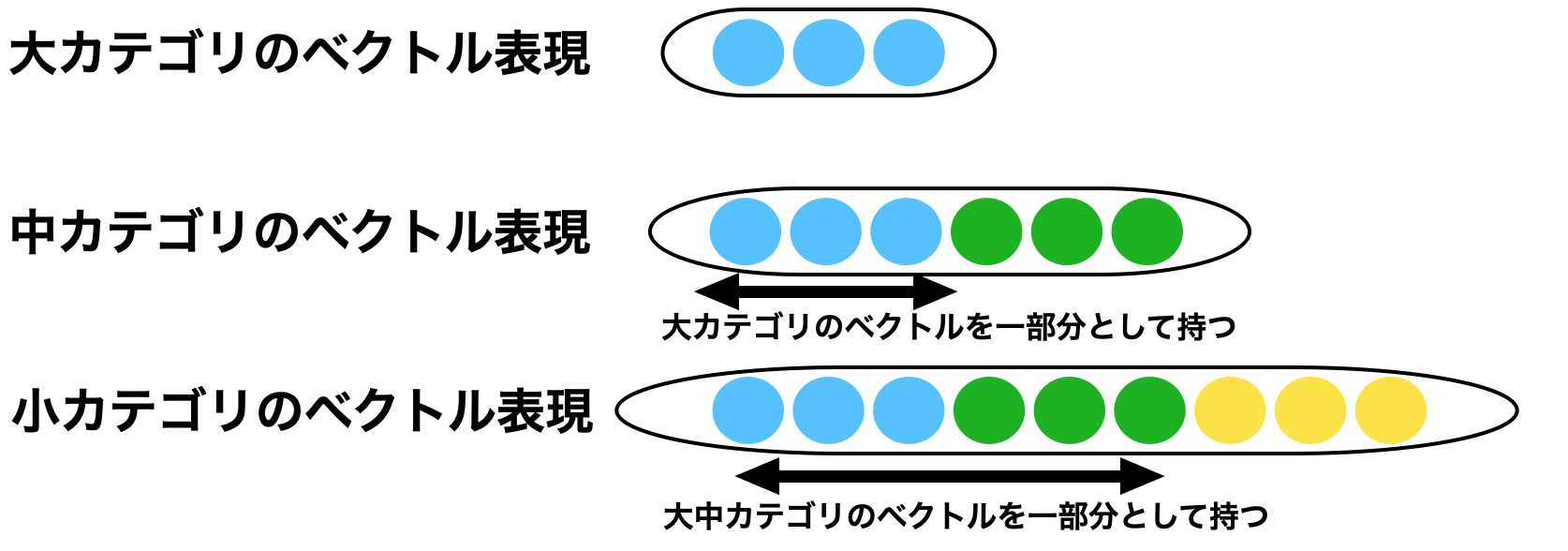
図2: カテゴリのベクトル表現 ((Gao et al., 2020) Figure 2 を参考に作成)
口コミ分析
続いては口コミ分析です。
もともと口コミという言葉は「人の口から口へと個別的に伝えられるコミュニケーション」を意味し、マスメディアを通して不特定多数に情報を届けるマスコミュニケーションと対比される言葉でした。しかし現在では、その意味も少し変化してきています。
SNS・ブログといった消費者生成メディアが台頭し、誰もが情報の発信者になれる時代となりました。
最近では本来の意味の口コミだけではなく、消費者生成メディアによって発信される一消費者による商品・サービスの感想・評価・批評なども口コミに含むことがほとんどです。
本記事でも、消費者生成メディアを通した消費者の言葉も口コミに含むものとします。
ECサイトには口コミの投稿・閲覧機能を持つものが多くあります。
みなさんの中にも、何かを購入する際に口コミを参考にした経験のある方は多いのではないでしょうか。
口コミは商品・サービスの消費者と供給者、双方にとって有益な情報源です。消費者は口コミを通して、商品が本当に購入に値するものなのか判断する材料にすることができます。供給者は口コミを読んで商品開発や広告の打ち方のヒントにすることができます。
しかしどちらにしても、口コミの数が増えてくるとすべての口コミをじっくり読み込んで分析することが困難になります。
さらに近年では、ECサイトで購入した商品の感想を ECサイトの口コミ機能ではなく、自らのSNSアカウントで発信する人も増えています。 口コミを網羅的にチェックするのはより困難な状況になってきていると言えるでしょう。 そのような状況下で大量の口コミを効率よく活用するため、様々なタスクとアプローチが日々開発されているようです。
例えば Gautamら [2] は、口コミの中でも特にSNSに投稿されている "苦情" に着目し、SNSにおける商品やサービスへの "苦情" を抽出するタスクに取り組みました。
私も普段SNSを眺めていると、購入した商品に対する「返品するほどではないけれども誰かに聞いてほしい不満」の投稿をよく見かけます。
このタスクの困難な点は、SNSの投稿全体に対して「ある特定商品・サービスに対する苦情」の投稿は (余程メジャーな商品・サービスでなければ) 非常に少なく、「商品 Aへの苦情を検出するモデルを作ろう」と思っても、十分な量の教師データが用意できないことです。
Gautamらは、「苦情の投稿」と「苦情の投稿を見つけるための指標」を交互に抽出する手法を適用することで、少数の苦情の投稿を入力として大量の苦情の投稿を検出できるような手法を提案しました (図3) 。
最初に、人手で用意した少数の苦情の投稿から、「苦情の投稿を見つけるための指標」を抽出します。
この指標には、「投稿にある語句が含まれているかどうか」「投稿に含まれる単語のベクトル表現のクラスタリング結果」「投稿に含まれる単語の品詞」などがあります。
指標を抽出したら、今度はその指標を使って、大量のSNSの投稿の中から苦情の投稿を検出します。
より多くの苦情が投稿できたら、さらにそれを使ってもう一度指標を抽出し・・・・・・というように、苦情と指標を交互に抽出しながら検出される苦情の数を増やしていきます。
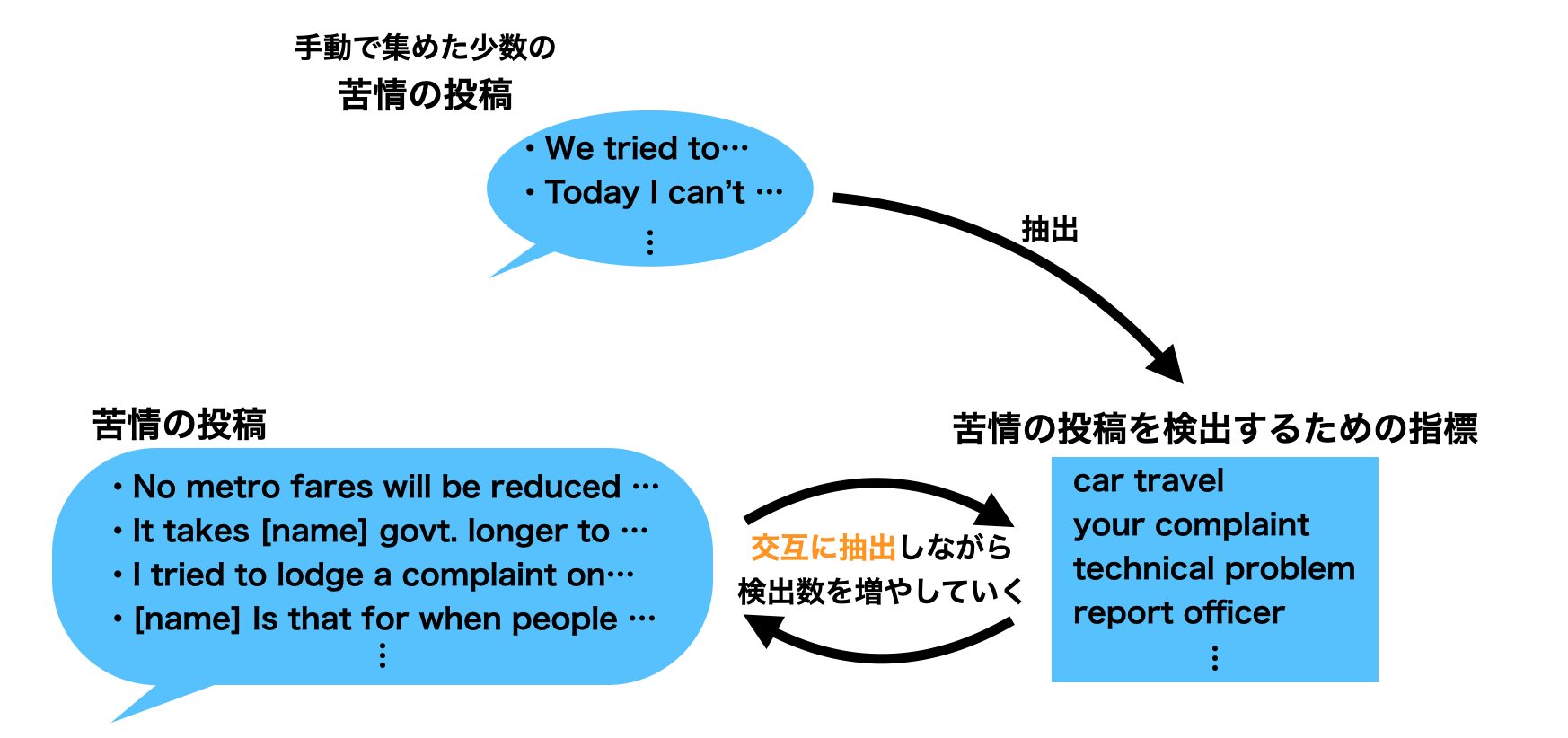
図3: 苦情の検出
ちなみに、このような少数のラベル付きデータと大量のラベルなしデータを使って行う機械学習を「半教師あり学習」と呼びます。
今回は苦情であることがわかっている少量の投稿と苦情であるかないか不明な大量の投稿をもとに学習を行う「半教師あり学習」ですね。
ラベル付きデータを大量に用意して学習を行う「教師あり学習」や、ラベルなしデータから学習を行う「教師なし学習」と対比してこのように呼ばれます。
もしこのタスクを教師あり学習で解くとすると、「苦情であることがわかっている投稿」と「苦情でないことがわかっている投稿」を大量に用意する必要があります。
また、このタスクを教師なし学習で解こうとすると、学習用のデータは単にSNSの投稿を集めるだけでよいのですが、今度は苦情であるかないかの基準をモデルに教えることが難しくなりますね。
Gautamらは評価実験として、実際の交通サービスの苦情を検出する実験を行いました。 最初は326個の苦情からスタートして苦情の投稿の抽出と言語的指標の抽出を4回反復し、2840個の言語的指標と3700件以上のツイートを収集しました。 収集した投稿のうち 700件の投稿をランダムに選んで確認したところ、47%以上が実際にその交通サービスを対象とした苦情だったそうです。
この実験は交通サービスが対象であったため ECサイトとは違いますが、ECサイト上で販売されている商品にも同じ手法を適用することができるでしょう。 小さなラベル付きデータを手動で用意することで、多くの抽出対象を抽出できる半教師ありの手法は、アカデミアでの研究とは異なり大規模データが手に入りづらい EC サイトでの自然言語処理でしばしば見かけます。
ここでは苦情の検出タスクを紹介しましたが、口コミ分析に対してもっと広く、もっと体系的に学んでみたい方は実践・自然言語処理シリーズ 第6巻 クチコミ分析システムの作り方がお勧めです。
おわりに
本記事では、カテゴリ予測・口コミ分析という代表的な2つのタスクを取り上げながら、ECサイトにおける自然言語処理について見ていきました。
ECサイトにおける自然言語処理の活用は、自然言語処理の最高峰の国際会議ACLでも EC × 自然言語処理をテーマとしたワークショップの第3回 (ECNLP3) が開かれるなど、盛り上がりを見せています(ちなみに、今回紹介した2本の論文も ECNLP3 で発表されました)。
今回取り上げることができなかったタスクの中にも、商品情報テキストからの情報抽出、検索キーワード入力の際のサジェスト、ある商品を見ている人への別の商品の推薦など、難しくも興味深いタスクがたくさんあります。ぜひ調べてみてください。
冒頭でも触れた通り、近年はフォルシアでも自然言語処理で検索を便利にしていこうという流れができつつあります。 今年4月には、検索キーワードの表記ゆれに対応するための検索辞書のクラウドサービス「WordFort」をリリースしました。
参考:フォルシア、検索辞書のクラウドサービス「WordFort」開始
私自身も業務でECサイトに携わっていますが、個人的には半教師ありの手法に特に注目しています。 ECサイトまわりの自然言語処理タスクではビジネス上・著作権上の理由から大規模なラベル付きデータが用意しづらいことが多いため、データ自体が大量にあればラベルがついているものが少数でも学習できるというのは魅力的です。
しかしそこにとらわれ過ぎず、まずは「何ができたら (顧客は/エンドユーザは) 嬉しいのか?」を継続的に考えていきたいと思っています。
参考
[1] Dehong Gao, WenjingYang, Huiling Zhou, Yi Wei, Yi Hu, Hao Wang. "Deep Hierarchical Classification for Category Prediction in E-commerce System." Proceedings of The 3rd Workshop on e-Commerce and NLP. 2020.
[2] Akash Gautam, Debanjan Mahata, Rakesh Gosangi, Rajiv Ratn Shah. "Semi-Supervised Iterative Approach for Domain-Specific Complaint Detection in Social Media." Proceedings of The 3rd Workshop on e-Commerce and NLP. 2020.
吉成 未菜里
新卒 1 年目のエンジニア。
理化学機器などを取り扱う EC サイトの開発・運用・保守やサマーインターンの企画を担当。



